Quick Guide | Pivot (SQL syntax)
Pivot tables can be one of the most useful tools in the arsenal of any developer as part of data profiling or analysis. It is a powerful tool for summarising and analysing data that allows you to see patterns and trends. The goal of this post is to provide a simple guide to pivot tables for analysis using SQL Server Management Studio Syntax.
Pivot Tables
A pivot table rotates or switches rows to columns to provide an easy-to-read format enabling quick analysis of data. For instance, you need to generate a dataset with client account balances accumulated over multiple transactions. The existing database table with balances looks like this:
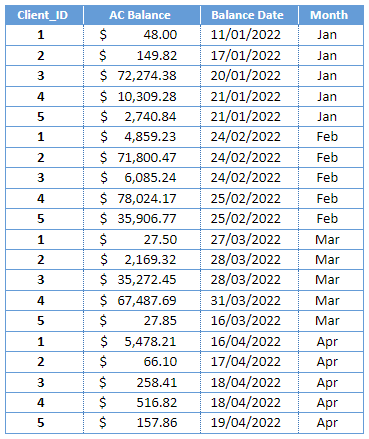
In order to quickly identify the client’s total outstanding amount, the data would need to be summarized. As such, we would need this table to look like the following:
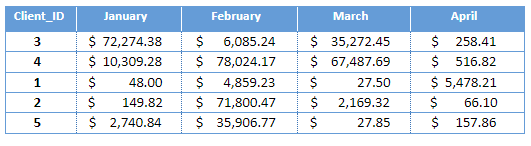
To achieve this, we would need to follow the steps outlined below:
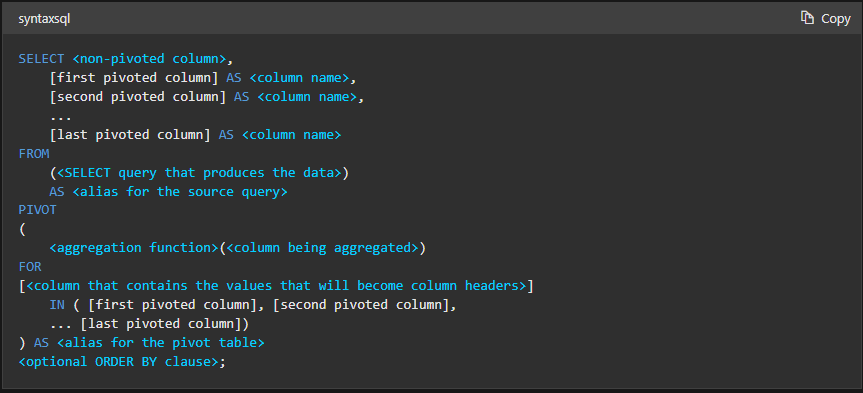
<code>
SELECT <non-pivoted column>,
[first pivoted column] AS <column name>,
[second pivoted column] AS <column name>,
...
[last pivoted column] AS <column name>
FROM
(<SELECT query that produces the data>)
AS <alias for the source query>
PIVOT
(
<aggregation function>(<column being aggregated>)
FOR
[<column that contains the values that will become column headers>]
IN ( [first pivoted column], [second pivoted column],
... [last pivoted column])
) AS <alias for the pivot table>
<optional ORDER BY clause>; Let’s break this down by the sections of the syntax.
- SELECT :
- The SELECT Statement refers to the columns we would like in our query
- Given our example listed above, our syntax would be listed as follows:
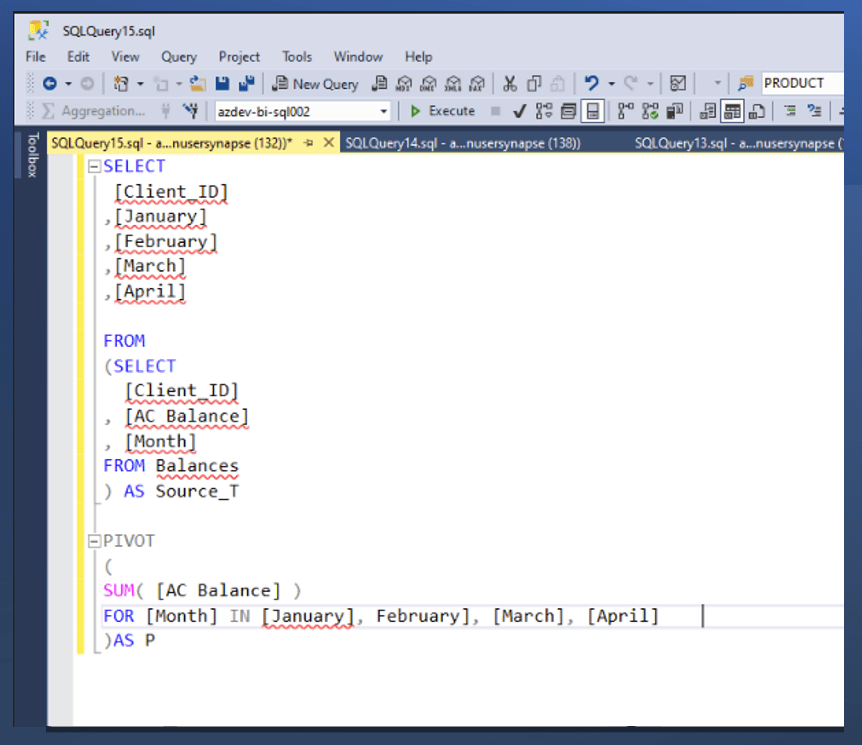
SELECT
[Client_ID] <non-pivoted column>
,[January] < first pivoted column >
,[February] < second pivoted column >
,[March] < third pivoted column >
,[April] < last pivoted column >
- FROM: SELECT query that produces the data:
- The FROM sections is where we set up our source query
- Given our example listed above, our syntax would be listed as follows:
FROM
(SELECT
[Client_ID]
, [AC Balance]
, [Month]
FROM dbo. Balances
) AS Source_T
- PIVOT: <aggregation function>
- The PIVOT function transforms the data from line item level to Client ID & Month summary level
- Given our example listed above, our syntax would be listed as follows:
PIVOT
(
SUM( [AC Balance] )
FOR <column that contains the values that will become column headers> [Month] IN [January], February], [March], [April]
) AS P <alias for the pivot table>
- Final Output:
SELECT
[Client_ID] <non-pivoted column>
,[January] < first pivoted column >
,[February] < second pivoted column >
,[March] < third pivoted column >
,[April] < last pivoted column >
<code>
SELECT
[Client_ID]
, [AC Balance]
, [Month]
FROM dbo. Balances
) AS Source_T
PIVOT
(
SUM( [AC Balance] )
FOR <column that contains the values that will become column headers> [Month] IN [January], February], [March], [April]
) AS P
Source: Microsoft (https://docs.microsoft.com/en-us/sql/t-sql/queries/from-using-pivot-and-unpivot?view=sql-server-ver16 )

David Gnanamuttu
Are you interested in knowing more about it?
Let’s talk, we can help you!
Check out the Lucid Insights blog
There is a variety of content that may help you to improve your business!